
本篇是爬蟲、資料清理的練習。希望藉由網路上咖啡豆賣場的商品資料,了解「單一產區咖啡豆」(以下簡稱單品咖啡豆)的價格分布、商品種類分布與不同處理、烘焙方式是否造成價格改變。
因篇幅的關係,下面的程式碼只會擷取部分做為參考。若要觀看完整程式碼,可以點選文章最底部的 GitHub 連結唷!
取得資料
首先我們從 12 家咖啡豆電商的擷取其「商品名稱」與「價格」。這些電商的規模大至連鎖店,小至地區性的小商家。
Import package
這次的爬蟲使用Selenium來進行爬取,並用Pandas與RE進行資料處理。
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
import re執行爬蟲並儲存資料
因為要爬取12個網站的內容,所以把它寫成函式以利重複使用。如果之後要爬其他網站,也可以用這個函式進行。
"""爬取資料"""
def crawler(url, low_length, high_length, value):
driver = webdriver.Chrome('chromedriver.exe')
driver.get(url)
try:
data = []
EmptyList = []
for i in range(low_length, high_length): # 執行爬蟲
data.append(driver.find_elements(by=By.XPATH, value=value % i))
for i in range(len(data)):
if data[i] != EmptyList: # if data[i] 裡面有值,則將值轉換成 text,反之 break
data[i][0] = data[i][0].text
else:
break
except ValueError:
print('value error')
else:
print('No Problem')
finally:
print('End')
driver.quit()
return data
"""to_excel"""
def download(data, filename):
data = pd.DataFrame(data)
data.to_excel("coffee bean analysis/%s.xlsx" % filename)
return 0清理資料
爬下來的資料總是充滿各種不利於分析的符號、額外資訊。因此,這一步要做的是把下圖出現的雜訊清理乾淨,並依照「咖啡豆」、「產地(國家)」、「產區」、「處理廠\莊園」、「烘焙度」、「處理法」、「價格」、「其他」分門別類放在相對應的欄位。

進行初步清理
不同網頁會有不一樣的排版格式,所以我們必須為資料量身訂做指令來進行清理。這邊只舉其中一個店家的資料作為參考。
除了用 Python 清理以外,有些比較好處理的資料就用 Excel的 FIND, MID, LEN, LEFT 等函數來整理了。
"""data3"""
df3 = pd.read_excel('data3.xlsx')
del df3['Unnamed: 0']
df3['咖啡豆'] = df3[0]
del df3[0]
df3['咖啡豆'] = df3['咖啡豆'].replace(r',', '', regex=True)
df3['半磅'] = df3['咖啡豆'].str.extract(r'~ NT\$(\d+)') # 將價錢跟品名區隔開
# print(df3['半磅'].isnull())
# print(df3['咖啡豆'][11])
df3['半磅'][11] = 3850*2 # 因為只有一個 null 所以手動補值就好
df3['咖啡豆'] = df3['咖啡豆'].replace(r'\nNT.*', '', regex=True)
# 將一磅的價格全部除以2,就是半磅了
for i in range(len(df3)):
df3['半磅'][i] = int(df3['半磅'][i]) / 2
print(df3)
# to_excel
df3.to_excel('data3.xlsx')合併多個表
所有資料都初步清理完成後,就可以把所以表格合併起來了。在 print 表格後會發現,同樣的商品會有不一樣的翻譯。
最常見的就是「耶加雪菲」,有些人會翻譯成「耶加雪夫」。這會造成之後在看數據的時候,同樣的商品被視作兩種不同商品。所以接下來主要是處理這類型造成的問題。不過資料量很多,也只能盡量挑了。
當初在做清理時,把 column 命名成中文,在打字時實在不方便。這邊也把它改回英文。
df['beans'] = df['beans'].str.replace("藝妓", '藝伎', regex=True)
df['beans'] = df['beans'].str.replace("瑰夏", '藝伎', regex=True)
df['beans'] = df['beans'].str.replace("耶加雪夫", '耶加雪菲', regex=True)
df['beans'] = df['beans'].str.replace("耶加雪非", '耶加雪菲', regex=True)將商品名稱依項目拆開
這是整個過程中最讓我頭痛的地方了。要怎麼拆?看過整體資料後會發現,裡面還有包含很多不是單品咖啡豆的品項,亦或是無法識別的商品名稱。像是下面的典藏咖啡豆、中烘焙黃金印象。

原本想藉著Jieba的分詞功能進行分詞,並以TF-IDF來找出重點詞彙。這樣的作法雖然可以知道資料中頻繁出現的詞是什麼,但依然沒有辦法做到「分類」。我想,TF-IDF應該是應用在,想要大略了解手上資料的重要詞彙時使用。
不過這個嘗試讓我想到可以借鏡Jieba的字典功能。為何不自己列一張國家國名的字典呢? 藉由字典中的國家與商品名稱比對,只要有對應到國家,就可以幫這個商品做標籤了。
接著,就可以開始幫資料分類啦!這邊也要多次使用,所以把它包成函式。
將每個商品名稱跟記事本的國家比對 → 比對到的就在新建的country欄位填入比對到的那個國家。
"""讀 dictionary"""
def to_txt(path, filename):
f = open(path, encoding='UTF-8')
temp_text = f.read()
f.close()
filename = temp_text.split('\n')
return filename
"""進行比對"""
def string_classification(filename, search_from, put_into):
"""
filename 是要使用的哪個 dictionary 的名稱
search_from 是要執行 str.contains 的 DataFrame column
put_into 是從 search from 找到目標之後,修改完要存取的位置。也是指定一個 DataFrame column
"""
for i in range(0, len(filename)):
put_into.loc[search_from.str.contains(filename[i])] = filename[i]
return 0
"""執行函式"""
# country
df['country'] = ''
country = to_txt('dictionary/country.txt', filename='country')
string_classification(country, df['beans'], df['country'])# country
df['country'] = ''
country = to_txt('dictionary/country.txt', filename='country')
string_classification(country, df['beans'], df['country'])完美地將國家分開啦!產區、烘焙法、處理法等欄位也是如法炮製。

清理不屬於單品咖啡豆的 rows
全部完成後,我們可以預期只要是不屬於單品咖啡豆的商品在 country, towns 都會呈現 NaN。我們只要移除這些欄位就可以大功告成囉!

# 移除 country 與 towns 都是 NaN 的商品
df = df[-(df['towns'].isnull() & df['country'].isnull())]移除後,再印出表格,就不會看到 country, towns 都顯示 NaN 的情況了。
使用 isnull().sum() 查看各欄位空值情形,依然是保留很多的空值。這方面就無可避免了。因為每一個店家在標示商品名稱時,給予的訊息其詳細程度都不相同。有的只給國家、處理法、烘焙度;有的只給產區、處理法;有的只給產區、烘焙度等。
尤其 others 欄位是為了因應有些商家以品種,如藝伎;以族群,如曼特寧作為商品名稱而另立的欄位,因此他的空值特別多。
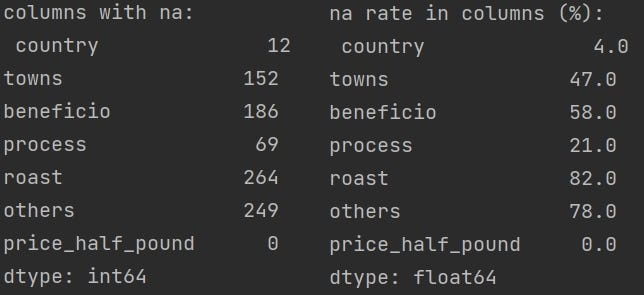
總之,這就是本次的爬蟲與資料清理練習。雖然之前有做過其他自然語言的爬蟲與資料清理,但這是第一次嘗試把資料切得這麼細。在切資料的這方面收穫良多。